
 九游会j9·游戏「中国」官方网站九游会J9
九游会j9·游戏「中国」官方网站九游会J9
2025年1月中旬,英伟达CEO黄仁勋的中国之行引人注目。从北京到深圳,再到台中庸上海,这位AI期间的“卖铲东说念主”每到一处都掀翻一阵上涨。关联词,就在距离英伟达上海办公室仅200公里的杭州,一场足以撼动AI产业方法的风暴正在悄然酝酿。彼时,身家1200亿好意思元的黄仁勋能够并未雄厚到,一家名为深度求索(DeepSeek)的低调中国公司,行将在7天后成为英伟达的“黑天鹅”。
从1月20日推理模子DeepSeek-R1开源于今13天来,DeepSeek引起环球的诧异,英伟达市值一周挥发5520亿好意思元,硅谷巨头惧怕,华尔街躁急。

图片起首:视觉中国
当通盘东说念主还在艳羡DeepSeek的惊东说念主实力时,OpenAI终于坐不住了。当地时刻1月31日,OpenAI崇敬推出了全新推理模子o3-mini,并初次向免用度户通达推理模子。这是OpenAI推理系列中最新、成本效益最高的模子,刻下照旧在ChatGPT和API中上线。OpenAI可能计划开源、公开齐全想维链。在o3mini崇敬推出之时,OpenAI的首席践诺官Sam Altman(奥特曼)携一众高管在reddit回答网友问题,其间荒漠承认OpenAI往日在开源方面一直站在“历史诞妄的一边”。Altman暗意:“需要想出一个不同的开源战术”。
DeepSeek 的“闪电战”:
性能、价钱与开源三重冲击
1月21日,特朗普在白宫书记启动四年总投资5000亿好意思元、名为“星际之门”(Stargate)的AI基础设施运筹帷幄。
前一天(1月20日),DeepSeek悄然开源了推理模子DeepSeek-R1。
随后,英伟达我方的科学家Jim Fan率先解读出了它的颠覆性真谛真谛。他说:“咱们生存在这么一个期间:由非好意思国公司延续OpenAI最初的处事——作念信得过通达的前沿研究、为通盘东说念主赋能。”
关联词,那一周环球的眼神都聚焦在刚刚上任的特朗普身上。
但周边周末,DeepSeek俄顷成为科技圈、投资圈和媒体圈连系的对象。摩根大通分析师Joshua Meyers说:“周五,我收到的问题95%都是围绕Deepseek的。”
有商场挑剔员预言,DeepSeek是“好意思国股市最大的恫吓”。
但为时已晚,英伟达的跌势照旧开动。1月24日(周五)英伟达股价跌去3.12%。1月27日(周一),英伟达遇到17%的“历史性”大跌,市值挥发近6000亿好意思元,黄仁勋的个东说念主钞票通宵之间缩水208亿好意思元。本周,英伟达累跌15.8%,市值挥发5520亿好意思元。
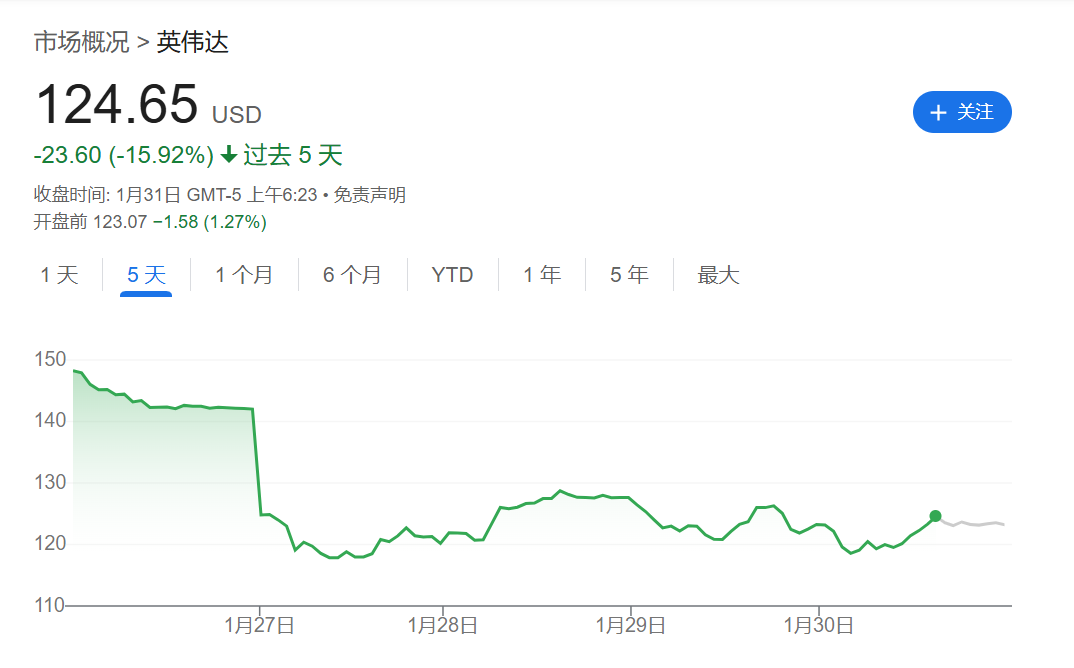
DeepSeek-R1带来的最径直冲击来自三个方面:性能、价钱和开源。
性能比肩 o1
1月24日(周五)发布的聊天机器东说念主竞技场(Chatbot Area)榜单上,DeepSeek-R1详细名轮番三,与OpenAI的ChatGPT o1并排。在高难度指示词、代码和数学等本领性极强的鸿沟以及作风完毕方面,DeepSeek-R1位列第一。
“白菜价”颠覆商场
DeepSeek-R1的价钱低得惊东说念主:API端口缓存掷中1元/百万Tokens,缓存未掷中4元/百万输入 tokens,输出16元/百万Tokens。仅为o1的2%~3%。
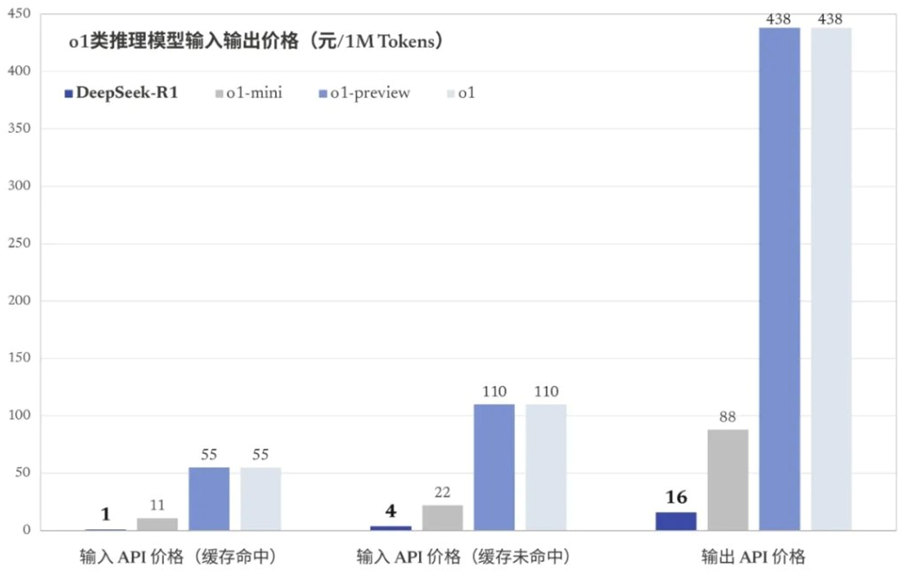
DeepSeek迁徙应用和网页端免费,而智商相配的 ChatGPT o1一个月200好意思元。
都备开源
DeepSeek-R1都备开源,任何东说念主都不错解放地使用、修改、分发和交易化该模子,透顶突破了以往大型语言模子被少数公司足下的时局,将AI本领交到了重翻开荒者和研究东说念主员的手中。
1月24日,有名投资公司A16z的创始东说念主马克·安德森发文称,Deepseek-R1是他见过的最令东说念主艳羡、最令东说念主印象深刻的突破之一,而且如故开源的,它是给寰宇的一份礼物。
最具挑动性的评价来自Scale AI创始东说念主亚历山大·王(Alexandr Wang)。他说:往日十年来,好意思国可能一直在AI竞赛中当先于中国,但DeepSeek的AI大模子发布可能会“改变一切”。
华尔街的躁急:DeepSeek动摇了
英伟达的“算力信仰”吗?
比拟于本领,投资者更暖热我方投资的公司将遇到如何的挑战。
他们开动想考,如若DeepSeek的低成本测验灵验,是否意味着巨头们在算力上的参加不值得了。如若不需要苟且参加,商场对英伟达的功绩预期还有撑握吗?
正如投行Jeffreies股票分析师Edison Lee团队1月27日在研报中所说,如今好意思国AI企业的不停层可能靠近更大的压力。他们需要回答一个问题:进一步提高AI本钱开销是否是合理的?
硅谷公司还靠近着投资者的拷问。1月27日上昼,高盛分析师Keita Umetani和多名投资者进行了话语,不少投资者质疑:“如若莫得酬劳,还能诠释本钱开销的合理吗?”

图片起首:视觉中国
随后,华尔街投行们纷繁发布表露安抚商场。
摩根大通分析师Joshua Meyers说,DeepSeek的(低成本)并不虞味着推广的闭幕,也不虞味着不再需要更多的算力。
花旗分析师Atif Malik团队称,尽管DeepSeek的设立可能是创举性的,但如若莫得使用先进的GPU对其进行微融合/或通过蒸馏本领构建最终模子所基于的底层大模子,DeepSeek的设立就不可能完毕。
DeepSeek-R1的测验成本尚未公布。因此,一个月前(前年12月26日)发布的开源模子DeepSeek-V3成为主要分析对象。
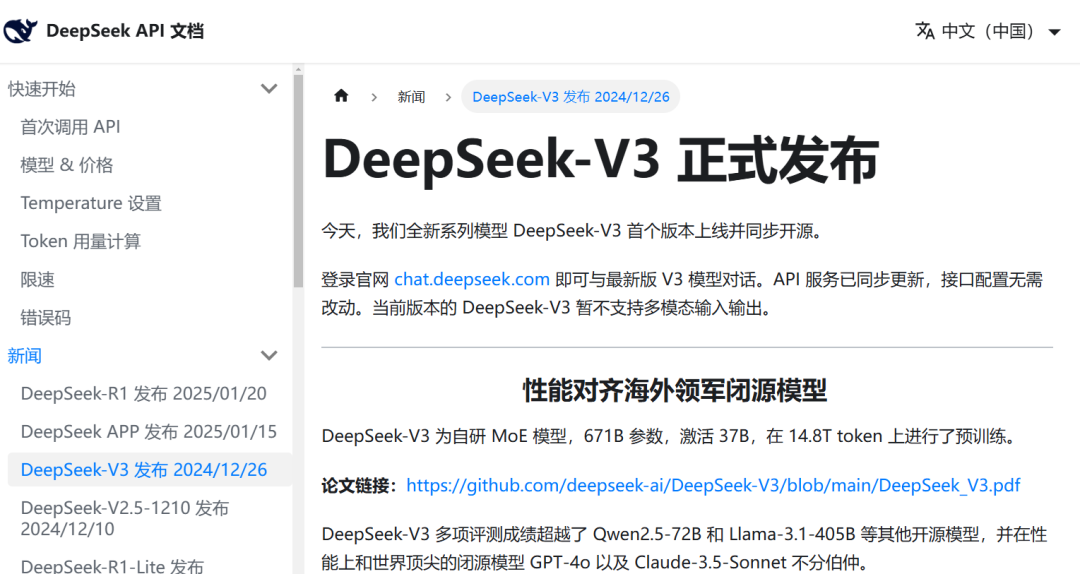
DeepSeek-V3仅使用2048块英伟达H800 GPU,在短短两个月内测验完成。H800是英伟达特供中国商场的AI芯片,在性能上不足先进的H200、H100等。
官方宣称的558万好意思元仅仅测验开销,的确总开销尚无定论。《DeepSeek-V3本领表露》中明确指出:请防卫,上述成本仅包括 DeepSeek-V3的崇敬测验,不包括与架构、算法或数据干系的先前的研究或精简实验的成本。
“当部门里一个高管的薪资就高出测验通盘DeepSeek-V3的成本,而且这么的高管还特别十位,他们该如何向高层派遣?”Meta职工如是说。
DeepSeek测验成本低,一个困难原因是使用了数据蒸馏本领(Distillation)。数据蒸馏是将复杂模子的常识索要到省略模子。通过已有的高质料模子来合成极少高质料数据,并作为新模子的测验数据。
凭证本领表露,DeepSeek-V3运用DeepSeek-R1模子生成数据后,再使用巨匠模子来蒸馏生成最终的数据。
不外,数据蒸馏本领在行业内充满争议。南洋理工大学研究东说念主员王汉卿向《逐日经济新闻》记者暗意,蒸馏本领存在一个巨大曲折,就是被测验的模子(即“学生模子”)没法信得过超越“教师模子”。OpenAI也把DeepSeek的蒸馏算作靶子加以挫折。
1月29日,OpenAI首席研究官Mark Chen发帖称,“外界对(DeepSeek的)成本上风的解读有些过甚”。
不外,DeepSeek-V3的改革不仅于此。
资深业内东说念主士向每经记者分析称,DeepSeek-V3改革性地同期使用了FP8、MLA(多头潜在防卫力)和MoE(运用羼杂巨匠架构)三种本领。
相较于其他模子使用的MoE架构,DeepSeek-V3的更为精简灵验,每次只需要占用很小比例的子集巨匠参数就不错完成酌量。这一架构的更新是2024年1月DeepSeek团队提议的。

图片起首:arXiv
MLA机制则是都备由DeepSeek团队自主提议、并最早作为核神思制引入了DeepSeek-V2模子上,极地面镌汰了缓存使用。
本剖析线之争:DeepSeek 的“原创”
与 OpenAI 的“空隙出遗迹”
2024年12月,清华大学酌量机系长聘副老师、博士生导师喻纯在谈及中国AI发展时向《逐日经济新闻》暗意,中国在AI应用层有很大的上风,擅长“从1到10”,但原始改革智商(从0到1)还有待提高。
刻下,这一办法可能不再适用了。
DeepSeek带来的最大“飘荡”,是蹚出了一条与OpenAI迥然相异的模子测验旅途。
传统上,监督微调 (Supervised Fine-Tuning,简称 SFT)作为大模子测验的中枢门径,需要先通过东说念主工标注数据进行监督测验,再勾引强化学习进行优化,这一范式曾被觉得是 ChatGPT成效的关节本剖析径。
但是,DeepSeek-R1-Zero是首个都备摈弃了SFT门径、而都备依赖强化学习(Reinforcement Learning,简称 RL)测验的大语言模子。DeepSeek-R1恰是在R1-Zero的基础上进行了阅兵。
英伟达高等研究科学家Jim Fan用大口语解释说:
SFT是东说念主类生成数据,机器学习;
RL是机器生成数据,机器学习。
这一突破为AI的自主学习范式提供了困难的践诺轨范。
DeepSeek为何不走捷径,而是寻求一条与OpenAI都备不同本剖析线?背后的根由不错从创始东说念主梁文锋的遐想中探寻。
《逐日经济新闻》记者了解到,DeepSeek轨则职工不行对外承袭采访。即即是DeepSeek用户群里的客服办当事人说念主员在解答群友疑问时亦然小心翼翼,字斟句酌。
寻找梁文锋的东说念主更是磨穿铁鞋。外界对他的了解大多来自于2023年5月和2024年7月《暗涌》对他的专访。专访著作将他称为“一个更极致的中国本领遐想主义者”。和OpenAI创始东说念主山姆·阿尔特曼(Sam Altman)通常,梁文锋的“方针地”是通用东说念主工智能(AGI)。关联词,梁文锋的遐想不在于方针地,而是如何通往方针地。
DeepSeek聘请“不作念垂类和应用,而是作念研究,作念探索”“作念最难的事”“惩处寰宇上最难的问题”。
梁文锋口中的“难”,就是“原创”二字。
他说:“咱们常常说中国AI和好意思国有一两年差距,但的确的gap是原创和效法之差。如若这个不改变,中国耐久只然而奴婢者,是以有些探索亦然逃不掉的。”
对于聘请和OpenAI不通常的路,梁文锋的语气中充满乐不雅:ChatGPT出身在OpenAI“也有历史的有时性”“OpenAI也不是神,不可能一直冲在前边”。
当地时刻周一(1月27日)晚间,OpenAI首席践诺官山姆·阿尔特曼终于对DeepSeek给出了他的评价。他在酬酢平台X上连发三条值得玩味的帖子。
起程点,他重申了我方的方针——AGI。致使比梁文锋更进一步,要“超越”AGI。
其次,他捍卫了我方的“蹊径”——算力不仅困难,而且前所未有地困难。
临了,他将DeepSeek-R1称作“一位新敌手”,并暗意“咱们天然会推出更好的模子”。
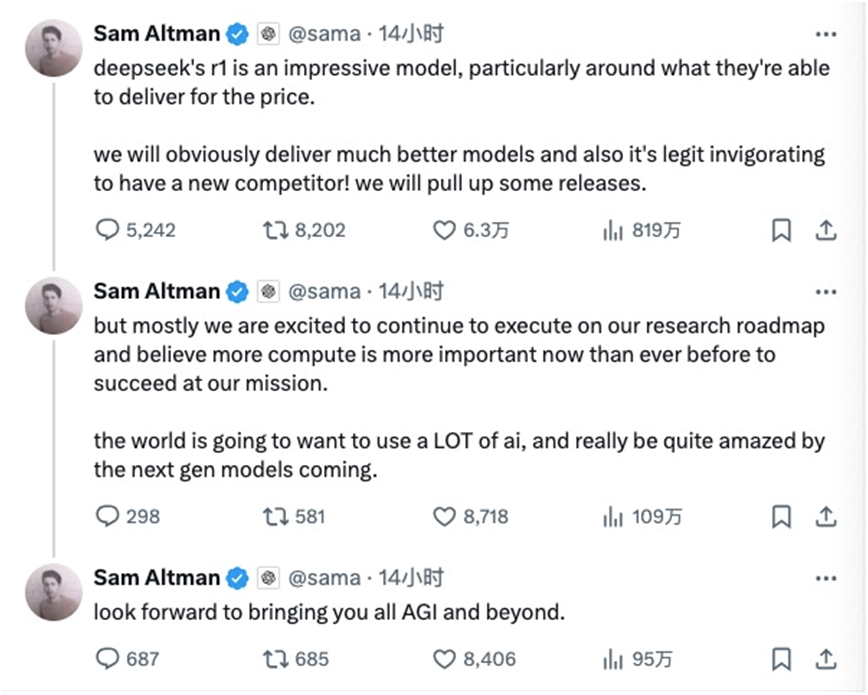
当地时刻1月31日,在携一众高管在reddit上举行AMA(问我任何问题)步履时,阿尔特曼崇敬承认DeepSeek是一个相配好的模子,OpenAI会制作出更好的模子,但当先上风会比以前收缩。
这是否是山姆·阿尔特曼向DeepSeek下的“讲和书”?他想较量的不仅对于谁是“更好的模子”,更是想用“空隙出遗迹”的本领与“灵敏”的本领进行一场比拼。
产业生态的博弈:
微软、英伟达、AWS纷繁接入
一边是硅谷、华尔街都在舌战DeepSeek的影响;另一边,科技巨头照旧下场无缝陆续DeepSeek-R1模子服务。
先是微软,当地时刻1月29日,将DeepSeek-R1模子添加到其Azure AI Foundry,开荒者不错用新模子进行测试和构建基于云的应用步和洽服务。
1月29日的第四季度功绩电话会上,微软首席CEO萨提亚·纳德拉(Satya Nadella)再次细目了DeepSeek“如实有一些信得过的改革”,况且书记DeepSeek-R1已可通过微软的AI平台Azure AI Foundry和GitHub获取,并将很快在微软AI电脑Copilot+ PC上运行。
天然微软是OpenAI的深度投资者且有许多合营,但在家具交易化上它依然聘请种种性的模子。刻下Azure的平台上既有OpenAI的GPT系列、Meta的Llama系列、Mistral的模子,刻下新增了DeepSeek。
紧接着,AWS(亚马逊云科技)也书记,用户不错在Amazon Bedrock和Amazon SageMaker AI两大AI服务平台上部署DeepSeek-R1模子。
再然后是英伟达于当地时刻1月31日官宣,DeepSeek-R1模子已作为NVIDIA NIM微服务预览版,在英伟达面向开荒者的网站上发布。
英伟达还在官网中暗意,DeepSeek-R1是一个具有起先进推明智商的通达模子。DeepSeek-R1等推理模子不会提供径直反映,而是对查询进行屡次推理,选定想路链、共鸣和搜索方法来生成最好谜底。此前,1月28日,英伟达(中国)在对每经记者的复兴中说到:“推理经过需要多量英伟达GPU和高性能相聚。”
想要在AI算力鸿沟挑战英伟达的AMD也绝不瞻念望为DeepSeek“站台”。1月25日,AMD书记,DeepSeek-V3模子已集成至AMD InstinctGPU上,并借助SGLang进行了性能优化。这次集成将助力加快前沿AI应用与体验的开荒。
阿斯麦总裁兼CEO富凯1月29日暗意:“任何镌汰成本的事情,对阿斯麦来说都是好音问”,因为更低的成本意味着更多的应用场景,更多应宅心味着更多芯片。
DeepSeek冲击波的真切影响:
AI的改日,何去何从?
2020年1月,OpenAI发表论文《神经语言模子的限度法例》(Scaling Laws for Neural Language Models)。限度法例标明,通过增多模子限度、数据量和酌量资源,不错权贵普及模子性能。在AI鸿沟,限度法例被俗称为“空隙出遗迹”,亦然OpenAI的制胜法宝。
2024年底,AI界传出大模子进化遇到“数据墙”的音问。好意思国本领研究公司Epoch AI臆想,互联网上可用的高质料文本数据可能会在2028年破钞。图灵奖得主杨立昆(Yann LeCun)和OpenAI前首席科学家伊利亚•苏茨克维(Ilya Sutskever)等东说念主直言,限度法例(Scaling Law)已涉及天花板。
“空隙出遗迹”的诚恳拥趸——硅谷巨头们开动将千亿好意思元级的本钱参加算力。
这场“算力竞赛”的苟且进度从底下这些数据中可见一斑。

图片起首:每经制图
但是,DeepLearning创始东说念主吴恩达1月29日撰文提醒称,扩大限度(Scaling up)并非是完毕AI跳跃的独一途径。一直以来……东说念主们过度关注扩大限度,而莫得以更紧密入微的视角,充分嗜好完毕跳跃的多种不同神情。但算法改革正使测验成本大幅着落。
DeepSeek-R1开源于今照旧往日13天,对于它的连系还在陆续。
DeepSeek的出现让东说念主们开动重新注释开源的价值和风险,以及AI产业的竞争方法。这场由DeepSeek激发的“冲击波”,将对环球AI产业产生真切的影响。
改日的AI寰宇,是“空隙出遗迹”的陆续狂飙,如故“灵敏”本领的异军突起?是巨头足下的固化,如故百花都放的茂密?
DeepSeek出现,让AI界开动信得过严肃地想考改日:是陆续烧钱豪赌,如故让AI恶果交易化、子民化和普惠化?
跟着测验成本镌汰、本领训练以及开源,大语言模子将愈发成为一种世俗家具。
1月31日,Hugging Face结伴创始东说念主兼CEO托马斯・沃尔夫(Thomas Wolf)说:“我觉得东说念主们正在从对模子的狂热中镇静下来,因为他们明显,收获于开源……许多这类模子将会免费且可解放获取。”
正巧地是,同日,OpenAI崇敬推出了全新推理模子o3-mini,并初次向免用度户通达推理模子。这是OpenAI推理系列中最新、成本效益最高的模子,刻下照旧在ChatGPT和API中上线。在o3mini崇敬推出之时,Sam Altman携一众高管在reddit回答网友问题时,荒漠承认OpenAI往日在开源方面一直站在“历史诞妄的一边”。Altman暗意:“需要想出一个不同的开源战术”。
记者|王嘉琦
剪辑|程鹏 兰素英 盖源源
校对|陈柯名
封面图片起首:视觉中国(贵寓图)
 |逐日经济新闻 nbdnews 原创著作|
|逐日经济新闻 nbdnews 原创著作|
未经许可卤莽转载、摘编、复制及镜像等使用
如需转载请向本公众号后台苦求并赢得授权


◆◆◆ 往期推选 ◆◆◆
“每秒可能有上亿的暗物资穿过咱们体格”,中国科学家2400米地下捕捉暗物资,屡次刷新海外记载
120万元买香烟公司处事?毕业就背上无数债务……专案组民警:400余东说念主为进好单元,被骗8000万元,主犯竟一晚豪掷五六十万喝洋酒
创造历史!中国上市公司回购金额首超股权融资九游会j9·游戏「中国」官方网站九游会J9,本钱商场诱骗力大增(附407家实力公司)